TL;DR
In the AI distribution space, this is the most important shift since the ChatGPT App Store launched.
Apps are now surfacing inside Claude conversations, at the exact moment a user expresses intent. No directory visit. No knowing your app exists. No installing anything ahead of time.
The user types what they want. Claude pulls in the apps that match.
This is the beginning of a whole new discovery field, similar to the early days of SEO, we called it ADO - Agentic Discovery Optimisation (we’ll soon be releasing our full research paper and thesis on this topic).
This guide walks through what's actually happening on the ground, the patterns we're seeing right now, and how you can ensure your appearing organically for your target prompts.
What Happened
For the last 6 months, Claude's Connector ecosystem has been a you-have-to-know-it-exists world. You'd add a connector manually, search for one in the directory, or hear about it from someone else.
That just changed.
Claude is now deciding - in real time, based on what you ask - which apps to surface. Sometimes as a list of options. Sometimes as part of a clarifying question. Sometimes pulled directly into the workflow as the default tool. Either way, your app either shows up or it doesn't, and the user makes a decision based on what Claude chose to put in front of them.
Get Instant Access
Enter your email to read the full guide.
What Happened
For the last 6 months, Claude's Connector ecosystem has been a you-have-to-know-it-exists world. You'd add a connector manually, search for one in the directory, or hear about it from someone else.
That just changed.
Claude is now deciding - in real time, based on what you ask - which apps to surface. Sometimes as a list of options. Sometimes as part of a clarifying question. Sometimes pulled directly into the workflow as the default tool. Either way, your app either shows up or it doesn't, and the user makes a decision based on what Claude chose to put in front of them.
You can see the full annoucement here.
Importantly: this is not just happening for consumer apps and this is not just happening for launch partners. We're seeing this happen across hotel booking, travel, presentations, document creation, research, and more.
Quick Background - MCP & MCP Apps
Before we go deeper, one thing worth nailing down.
When we say "apps in Claude," we're talking about connectors in the Claude directory - and connectors are MCP & MCP Apps.
The Model Context Protocol (MCP) is the open standard Anthropic, OpenAI, Microsoft and many others have all adopted to let LLMs call external tools and surface data and app experiences directly inside the conversation.
If you want to be discovered organically inside Claude, the prerequisite is simple: you need a Claude Connector (MCP / MCP App) live in the directory. Without one, you cannot get organically discovered as there is nothing for Claude to surface.
The good news: an MCP / MCP App you build for Claude is largely portable. With minor updates, the same app can be deployed into ChatGPT, Microsoft Copilot, and the other major LLM clients adopting MCP & MCP Apps. One build, multiple distribution channels.
If you don't have an MCP App yet, or you want one built well, Ghost Team builds production MCP & MCP Apps for enterprises. If you want to talk about building one or getting help with testing and distributing your MCP App, get in touch.
How Organic Discovery Has Been Evolving Across AI Clients
Organic discovery isn't binary - it's a spectrum, and every major LLM client is moving along it at a different pace.
There are three states an app can be in, in any given client:
- Manual + named - User has to go to the directory, connect the app, and explicitly @mention it for the model to call its tools.
- Manual + organic invocation - User connects the app once, but doesn't have to mention it. The model decides when to use it once a user has it connected (similar to them having downloaded an app in the mobile era).
- Fully organic - User doesn't have to connect or mention anything to get surfaced an app. The client surfaces the right app at the moment of intent.
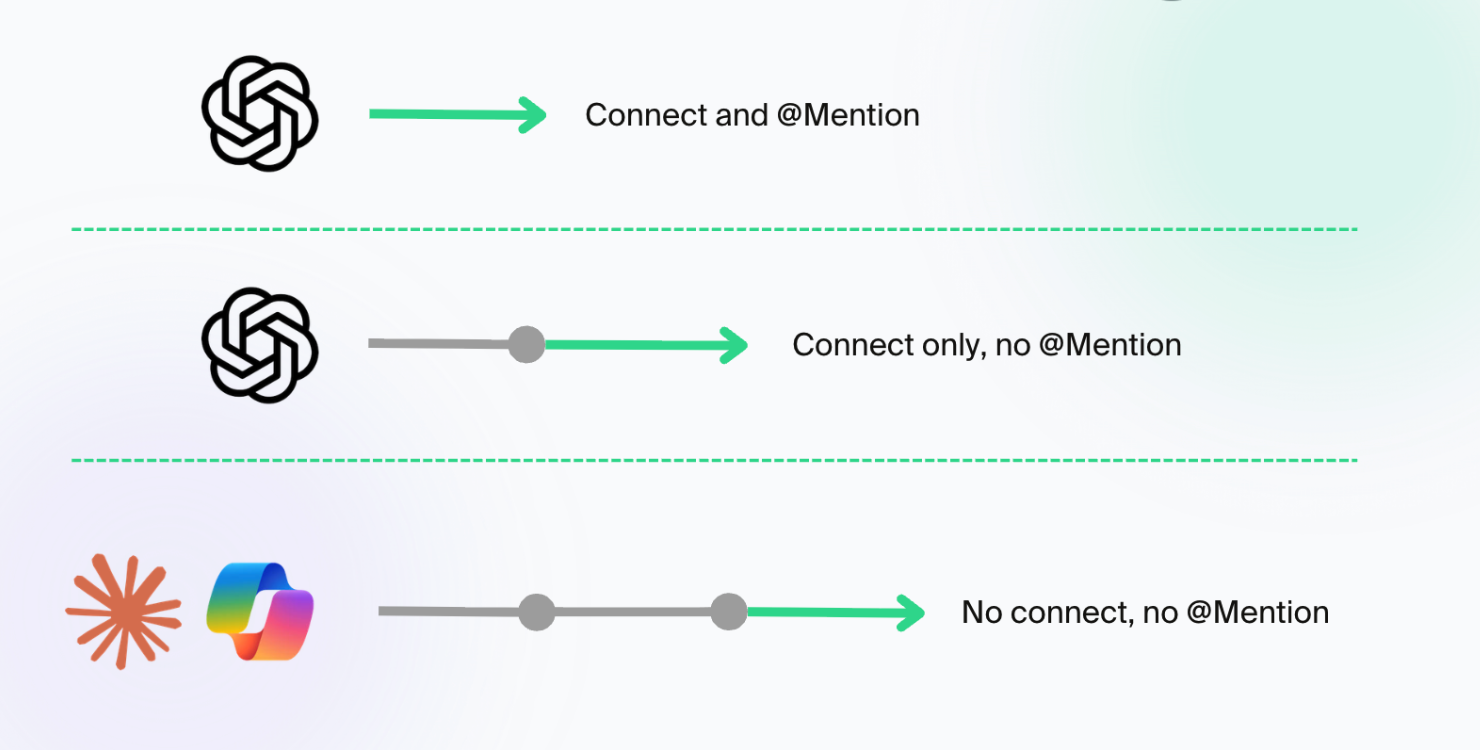
Here's roughly where the major clients sit today:
| Options | Connect required | Mention required | Organic surfacing |
|---|---|---|---|
|
| Yes | Sometimes - mention is no longer always required | No |
|
| Yes | No | Now live |
 Copilot (Microsoft)
Copilot (Microsoft)
| Yes | No | Yes (early, expanding) |
Claude has just made a significant move. Until recently, Claude required you to have already connected an app for the model to invoke it organically. Now Claude is surfacing apps to users before connection - pulling them into the conversation as suggested tools the user can connect and use in a single click.
That's the change this whole post is about. Claude has moved a full step along the spectrum.
What the Claude Connector Ecosystem Looks Like Today
We've been tracking every connector in the Claude directory daily since launch with our MCP App Intelligence platform. Here's what the data says as of April 24, 2026.
Connector growth over time
Claude opened the connectors directory in November 2025. In just under six months, the catalogue has grown to 353 live connectors.
April 2026 alone has already added more new connectors than any prior month - and we're only at the 24th. The pace is accelerating, not slowing.
Category breakdown
The catalogue isn't evenly distributed. A handful of categories dominate.
Claude is clearly leaning in on productivity and the B2B use case. Interestingly, in their announcement, they are now launching more B2C applications. I suspect this will continue and they'll try and take on more of the consumer market (and therefore, accept more consumer apps), further competing with OpenAI in this space.
Interactive apps vs. tool-only servers
Not every connector in the directory is the same kind of thing.
A connector can be either an interactive MCP app - one that ships with widget UI components Claude can render directly inline (think Gamma's slide preview, Booking.com's hotel cards) - or a tool-only MCP server that just exposes data and actions without rendering anything visually distinctive.
Of the 353 live Claude connectors:
- ~11% are interactive MCP apps - they have UI components Claude can render inside the conversation
- ~89% are tool-only servers - they expose tools but don't render rich, branded surfaces
The Two Ways Organic Discovery Is Showing Up
We're seeing two distinct patterns at the moment.
Option 1 - Claude Surfaces a List of Connectors
This is the most direct version. The user's intent maps to a category, and Claude returns a stack of relevant connectors with a Connect button next to each.
Example: hotel booking
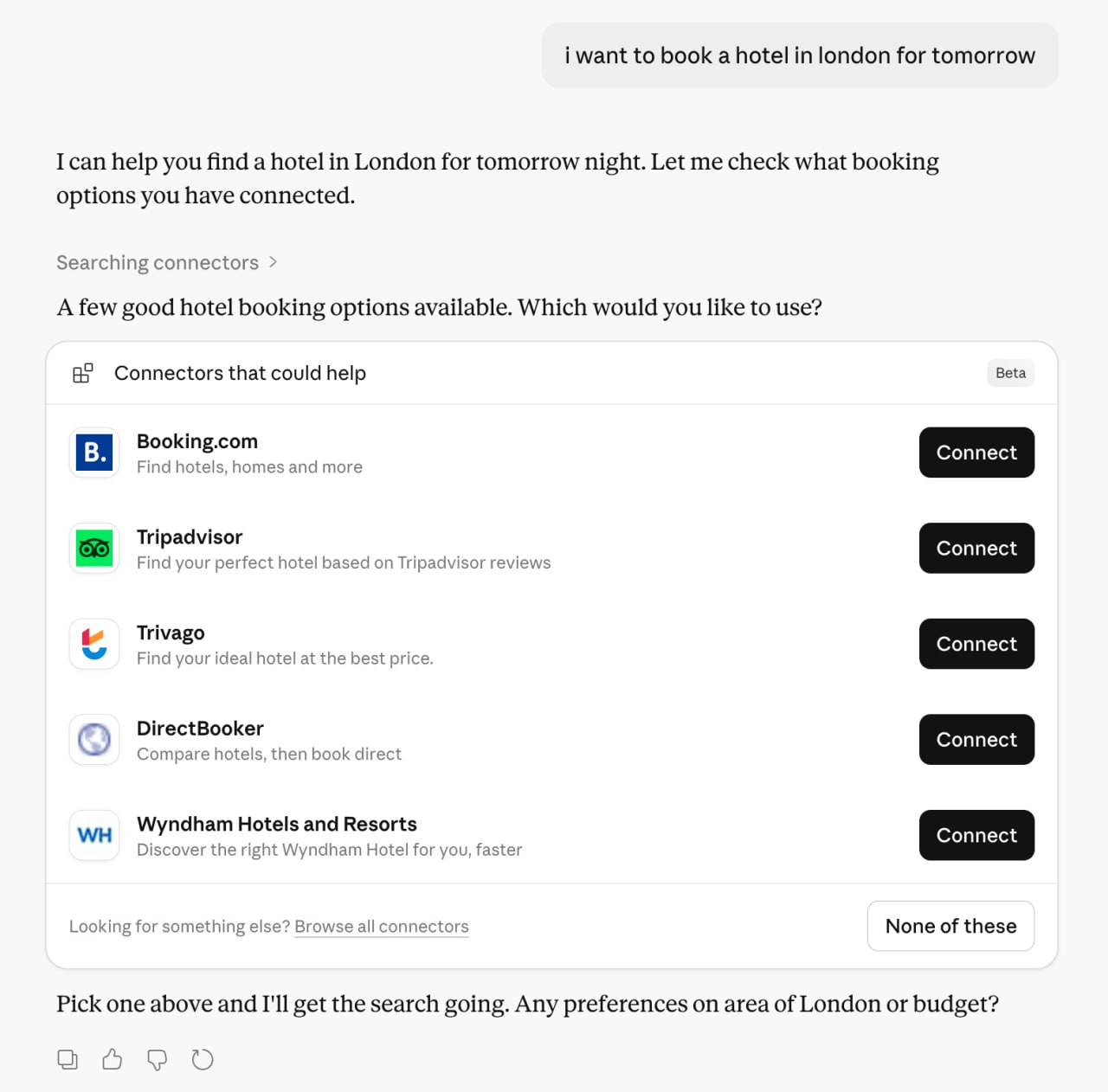
User types: "I want to book a hotel in London for tomorrow."
Claude responds: "A few good hotel booking options available. Which would you like to use?"
Then it serves up:
- Booking.com - Find hotels, homes and more
- Tripadvisor - Find your perfect hotel based on Tripadvisor reviews
- Trivago - Find your ideal hotel at the best price
- DirectBooker - Compare hotels, then book direct
- Wyndham Hotels and Resorts - Discover the right Wyndham Hotel for you, faster
Five apps, one prompt. The user picks one. The other four don't get the conversion.
There are two things you have to win in a surface like this:
- Are you on the list at all? This is the first cut. If Claude doesn't include you in the shortlist for this intent, nothing else matters - you weren't even an option the user could pick. Step one is making sure you're present for the prompts that matter to your business.
- Where do you rank on the list? Once you're on it, position is everything. Top of the list will likely convert better than bottom - the same dynamic everyone learned with Google search rankings. Users skim, they pattern-match the first option that fits their intent, and they pick.
If you sell hotel bookings and you're not in that list, you didn't lose to a competitor on price or features - you lost because Claude didn't put you on the shortlist. And if you're on the list but ranked last, you stand less of a chance to get selected then whoever is at the top.
Option 2 - Claude Surfaces Apps Inside Clarifying Prompts
This is the more subtle one.
When intent is broader (build a slide deck, write a doc, plan a trip), Claude asks clarifying questions - and the answer options themselves include specific apps.
Example: building a presentation
User types: "I want to create a slide presentation."
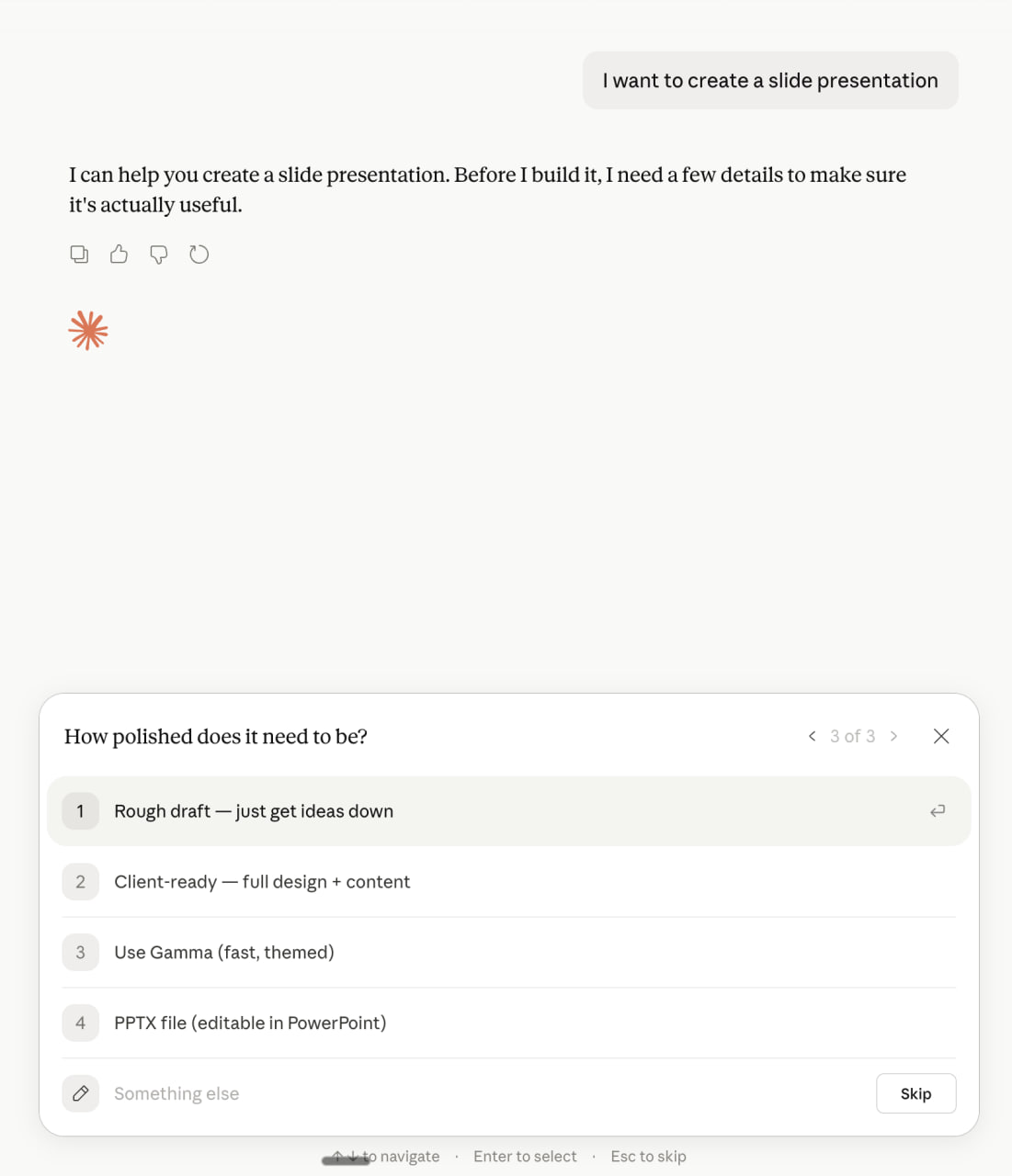
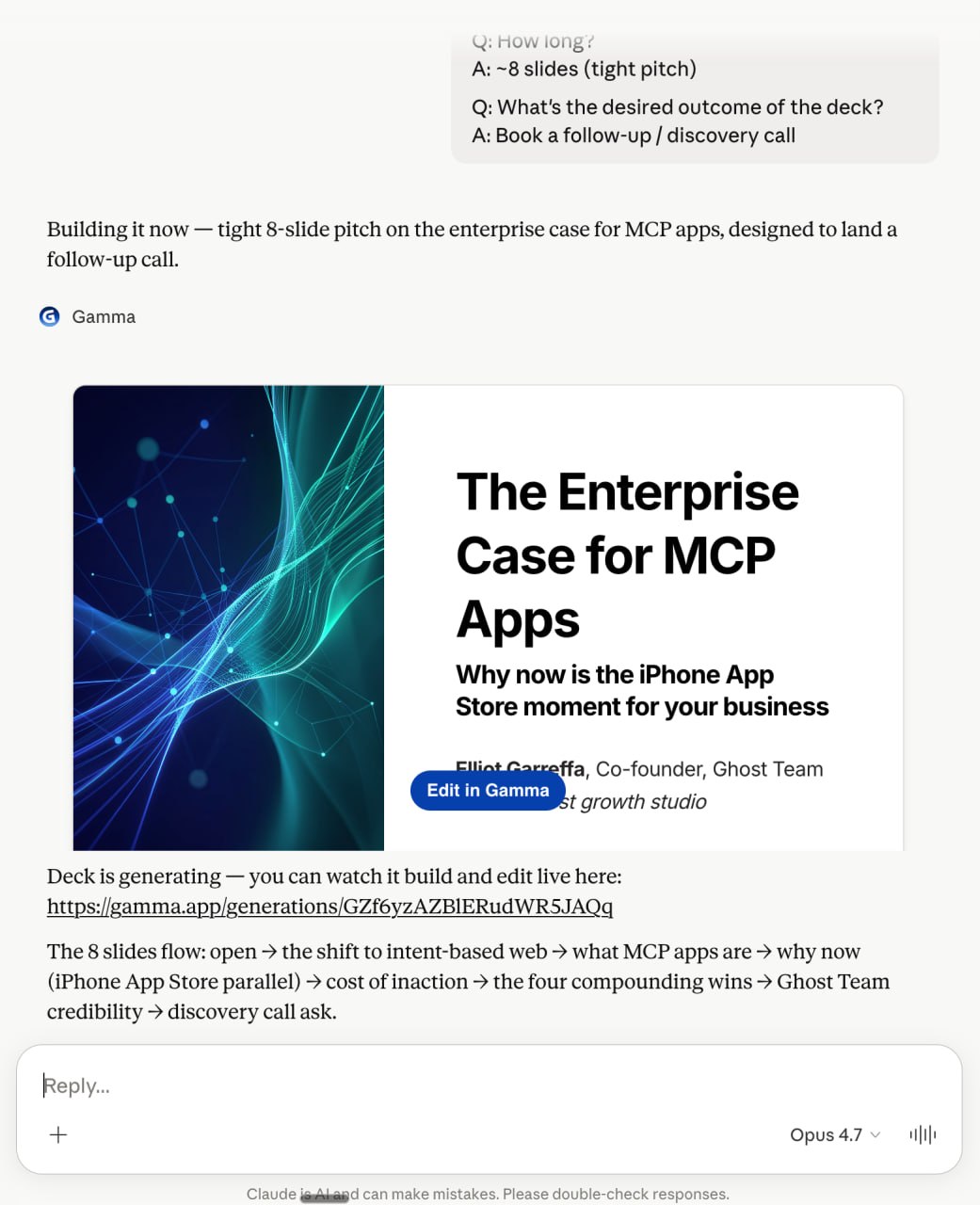
Claude asks: "How polished does it need to be?"
The answer options:
- Rough draft - just get ideas down
- Client-ready - full design + content
- Use Gamma (fast, themed)
- PPTX file (editable in PowerPoint)
Gamma isn't competing with "another presentation tool" here. It's competing with file formats and abstract polish levels - and it's winning by being the named option the user can tap.
That's huge for any app placed there. Apps embedded into Claude's clarifying logic become the default path for people who select an app with that intent.
We will be publishing more detail soon
We're tracking these variations of how Claude is surfacing apps, and more, in different conversation contexts, model versions, and account tiers - and the full discovery pattern guide is going out to the AgentDiscoverability platform soon.
If you want early access to the full breakdown of which apps are being discovered, in which patterns, and for which prompts, sign up to AgentDiscoverability.com and we'll be in touch.
How to Optimize For It
We recently spoke at the MCP Dev Summit on exactly this topic. The talk is called "If the LLM can't find you, you don't exist," and it covers the principles below in more depth.
Note: you can watch the full talk here: https://www.youtube.com/watch?v=aF7aCPJOjmc&t=2s
There's no magic trick. There's a process, and it's the same one we use across every enterprise we work with.
01 - Understand how you rank and perform
Before you change anything, you need to know where you actually stand.
Two things to measure:
- Rank is whether your app appears for the prompts that matter
- Performance is whether you're performing as expected - do your tools fire correctly and return what they should and do you even invoke at all
Done properly, this stage tells you:
- Are you appearing for your target prompts? When users ask for the thing your app does, does Claude pull you in - or does it surface a competitor? Which prompts are wins, which are losses, and how is that split changing over time?
- What does your appearance actually look like? Are you in Option 1 (the shortlist of connectors)? Option 2 (the named option inside a clarifying flow)? Are you ranked first, fourth, or buried at the bottom?
- What are competitors doing? Are they overtaking you on prompts you used to win? Has a new entrant just landed in the directory and taken your slot? Your rank matters individually and in relative terms to the apps Claude could pick instead.
- Is your app actually working as expected? You cannot be discovered if your app doesn't work. System prompts change, models change, based on our testing, many times apps aren't even being invoked at all. Tool errors, timeouts, malformed responses, and silent failures all have the same effect - the user bounces, and the model learns not to call you. Failure compounds: a tool that fails today gets called less tomorrow, which means lower rank, fewer chances to succeed.
Most teams skip all of this. They check rank with a few hand-crafted prompts in a local testing simulator and assume performance is fine.
Here's why local tests don't cut it: we routinely see up to a 60% gap between local simulation results and live in-client behaviour. The same prompt that fires perfectly against your MCP server in isolation can fail inside Claude or ChatGPT - because of system prompts, model version routing, free vs. paid tier degradation, geographic context, personalization, or competing tools loaded into the same conversation. None of that is visible from your server logs.
You can't understand rank or performance without conversational testing
Most teams test their apps with what OpenAI call golden prompts - perfectly phrased, hand-crafted inputs that more or less restate the tool name. Real users don't talk that way. We ran 5,000 prompts across four user personas, from "golden prompt user" through to "non-technical user with vague, messy, multi-turn phrasing," and saw a 20-point drop in invocation rate from one end of the spectrum to the other. Wrong tools chosen. Right tools ignored. All on the same underlying intent.
If you're only testing golden prompts, you're not measuring rank or performance. You're measuring a best case that almost no real user will ever hit.
To get an honest read on how your app is doing you need:
- Live in-client monitoring across the actual LLM clients your users are on (Claude, ChatGPT, Copilot)
- Persona-based conversational testing at scale - messy, indirect, multi-turn prompts that reflect how users actually phrase intent
- Invocation rates, tool error rates, and model version splits - not just whether the tool fires, but whether it succeeded
- Whether you're being found organically - for the target prompts that matter to your business, and how you're stacking up side-by-side against the category competitors fighting for the same intent
That's the dataset you need in front of you before any optimization decision is worth making.
If you want to track yours or a competitors apps rank and performance, sign up here →
02 - Optimize what agents choose
Once you have the data from step 1, you can do the work that actually moves the needle.
This is the part where data is non-negotiable. The data is what tells you what to change. Without it, you're guessing at tool descriptions and hoping. With it, you can see which prompts you're losing, which tools are erroring, which competitors are taking your placements, and which specific signal is dragging your rank down.
There are a lot of levers. Some of the signals that influence whether Claude organically selects your app are:
- Tool name - how clearly it telegraphs purpose
- Tool description - specificity, "use this when..." framing, differentiation from similar tools, every word is doing work
- App-level metadata - name, short description, long description, category placement
- Tool parameters and schemas - clarity, required vs. optional, examples
- Output structure - what the tool returns and how the model can use it next
- Ratings and approvals - directory-level signals about quality and trust
- Usage and traction - how much real-world activity an app has
Stanford research from earlier this year found nearly 100% of MCP tools have quality defects, and roughly half fail to clearly describe what they do. That's the gap we close for our clients.
We've run 15,000+ simulations across hundreds of live MCP apps, we track signals across every connector in the Claude and ChatGPT directories, and we constantly measure what is driving performance. We're not guessing at what works. We're seeing it in the data every day, and feeding that proprietary data back into improving the apps on our platform in a continuous loop.
If you want to optimise your app for performance and discovery based on our proprietary data set,
03 - Get Discovered (win organic intent)
This is the outcome.
Keep improving until your app appears naturally for the high-intent moments - the prompts where users are asking for exactly what you provide. Convert those high-potential users. Then feed the data back into step 1.
Discovery isn't static. Users change. Prompts change. Competitors change. Models change - sometimes daily. A description that ranks you #1 today can drop you off the list entirely after a system prompt update on the client side.
The teams that win organic discovery treat it like SEO in 2008: a continuous loop. Measure → optimize → improve rank → measure again. Every week. Every model update. Every new competitor that lands in the directory.
That's the cycle we run for our customers on a daily basis, and it's the cycle we make available to every builder on the AgentDiscoverability platform.
We've Been Tracking This Since Day One
We've spent the last 6 months building the largest dataset on how organic discovery actually works inside Claude and ChatGPT.

AgentDiscoverability.com's MCP App Intelligence platform tracks:
- 768 ChatGPT Apps - tracked daily, with full history reaching back to the launch of the ChatGPT App Store
- 353 Claude Connectors - every connector in the marketplace, monitored daily
- 532 new apps added in the last 30 days - the ecosystem is ramping up (ChatGPT App Store: 427 & Claude Connector Store: 105)
Every connector. Every touchpoint. Every ranking signal. Visibility scores, category breakdowns, growth over time, cross-platform presence - all of it.
We working with enterprises to design and build their MCP App, but importantly, also make sure it actually gets discovered for the prompts that matter to their business.
We were tracking this before it was live. We've spent 6 months learning what works and what doesn't. And we've shipped the platform that lets builders act on it.
You can also watch our talk at MCP Dev Summit in New York, which is run by the Linux Foundation, on principles for building MCP apps and what we've learned by shipping MCP apps for enterprises.
Sign Up to Get Better Organic Discoverability in Claude
If you want to:
- See whether your app is surfacing for the prompts that matter
- Track your competitors and know when they overtake you
- Get the metadata, positioning, and ranking insights that move the needle
- Get notified when Claude changes how it ranks apps (because it will)
- Improve your organic discovery inside Claude for your target prompts
Sign up at AgentDiscoverability.com - get better organic discoverability within Claude.
This is Day 1 of organic agent-driven distribution.
Get in early and start today.